Table of Contents
Nftables - Demystifying IPsec expressions
In this article I like to take a look at the expressions provided by Nftables for matching IPsec-related network packets. The common situation is that you need to distinguish packets from normal traffic, which either have been received through a VPN tunnel and already have been decrypted or packets which are to be sent out on a VPN tunnel, but have not been encrypted yet. Those kind of packets can be matched by these expressions within packet filtering rules. I'll explain how these expressions work, what they use as back-end, what their limitations are and how you can use them to get your intended behavior. Further, I take a short glimpse at the Iptables equivalent of these expressions.
Previous article
This is a follow-up to my previous article Nftables - Netfilter and VPN/IPsec packet flow, where I described how IPsec-related packets are managed within the kernel, in which sequence of steps IPsec policy lookups and the encryption/decryption actually happen and how packet flow looks like from Netfilter/Nftables point of view. I strongly recommend that you read that article, if you haven't already, because a lot of what I'll describe in the following sections presumes that you already obtained that knowledge.
Overview
No matter what your exact intentions are when applying packet filtering rules…
if your system is the endpoint of an IPsec-based VPN tunnel, then it is essential to be able to distinguish between VPN and non-VPN traffic. While it is rather trivial to identify already/still encrypted network packets by matching for the ESP protocol or for UDP port 4500 in case of Nat-traversal, it is not so trivial to identify packets which already have been decrypted or have not been encrypted yet. The latter kind of packets just look like any other traffic.
You could identify those packets in a rather crude way, e.g. by filtering according to the source/target IP address of a packet in case you know the subnet(s) of the VPN peer1). However, that does not check at all whether the
packet actually will be or has been processed by IPsec. Further, information like the CIDR notation of the peer subnet address often is dynamic data resulting from an IKE handshake. Thus, you might not
know it in advance and even if you do, it's a rather bad idea to statically hack it into your packet filtering rules, because it might change. Luckily the strongSwan IKE implementation provides a plugin with a hook script named _updown, which is called when the VPN tunnel either goes up or down. This script has access to such dynamic data and you can place commands to add/remove your dynamic packet filtering rules in there2).
One other way which simplifies distinction are so-called route-based VPN setups, which use virtual network interfaces. In case of IPsec those are either vti or xfrm interfaces.
Then you could simply filter IPsec traffic by matching against the ingress or egress network interface of a packet. However, the current IPsec implementation within the Linux kernel – the Xfrm framework –
does not use virtual network interfaces by default and can perfectly work without those.
This leaves you with the choice of using IPsec expressions provided by Nftables/Iptables. But how do they work and what do they use as back-end? Do they maybe cause additional queries/lookups into the IPsec SPD and SAD databases? That could work, but it would pose quite a performance penalty, which would argue against using them. Can you use them everywhere in the ruleset or just in specific chains/hooks and in the latter case which ones and why? Do they match already/still encrypted packets, too? Well, these all are questions which went through my head when I first encountered those expressions. Answering them is the purpose of this article.
Packet meta data
Network packets which are traversing the Linux kernel network stack are attached with a lot of meta data, which is required for management purposes, thus, to make sure each packet finds its correct way through the kernel. More to the point: Within the kernel, network packets are represented by so-called “socket buffers”, which are instances of struct sk_buff, often abbreviated as “skb”. Those structs provide pointers to actual buffers where the bits and bytes of the packet's network headers and payload are located, but they also provide a lot of additional member variables. This is the meta data I am talking about. Obviously that data is only temporary. It is discarded once the packet is either received by a userspace application or sent out on the network. Some of these member variables are used by the Xfrm framework to manage packets which are to be transformed by means of IPsec. And… spoiler alert… Nftables/Iptables IPsec expression make use of exactly that meta data. This means that these expressions do NOT cause any additional queries/lookups into the internal databases of the Xfrm framework. So, there is no performance penalty to worry about. They solely make use of what is already attached to a network packet at a certain point. In this context you'll have to distinguish between “outbound” and “inbound” IPsec packets, which I'll explain in the following.
Outbound IPsec packets
Outbound means packets which are to be encrypted3) by IPsec and then to be sent out on the network. So what meta data is relevant here?
When the routing lookup is performed, the resulting routing decision is being attached to the network packet as meta data. Function skb_dst(skb) can be used to obtain a pointer to it. This routing decision contains information like the output network interface, the IP address of the next hop gateway (if existing), function pointers which determine the path this packet takes through the remaining part of the kernel network stack, and more. However, after the routing lookup, IPsec performs a lookup for the output policy (dir out SP). If the packet matches, the attached routing decision is being replaced by something more complex, which is called a “bundle”. It is a collection of several things. Among those are a reference to the matching IPsec SP, a reference to the IPsec SA to be applied in this case (in other words, instructions for the Xfrm framework how to transform the packet), the original routing decision and in case of tunnel mode, yet another routing decision for the future outer IP packet. The actual IPsec transformation does not yet happen at this point. However, the packet can from now on be distinguished from non-VPN traffic based on this meta data. This is what the Nftables/Iptables IPsec expressions make use of.
Inbound IPsec packets
Inbound means packets which are received in encrypted form4) and have already been decrypted5) by IPsec. The relevant meta data in this case is the skb extension struct sec_path. This extension is being attached to the packet while it gets decrypted. It contains a reference to the IPsec SA which has been used to decrypt the packet. The Xfrm framework itself makes use of this mechanism so it can later recognize these kind of packets when doing lookups for the IPsec dir in or dir fwd policies. However, other components like the Nftables/Iptables IPsec expressions make use of that, too.
Nftables expressions
The Nftables IPsec expressions are implemented in kernel source net/netfilter/nft_xfrm.c and documented in Nftables man page man nft(8). Please search for the heading IPSEC EXPRESSIONS within the man-page. The syntax of these expressions is described there as the following:
ipsec {in | out} [ spnum NUM ] {reqid | spi} ipsec {in | out} [ spnum NUM ] {ip | ip6} {saddr | daddr}
So when applying one of these expressions, first of all you need to specify either ipsec in or ipsec out to specify whether the expression should examine the inbound or outbound policies as the man-page states. That explanation might be a little confusing. After all there actually are not two but three different IPsec policies and those are dir out, dir in and dir fwd. I explained the meaning of those policies in my previous article. What the man-page is actually saying is that ipsec in here specifies “inbound” IPsec packets and ipsec out specifies “outbound” IPsec packets as I described those in the sections above.
Further, you need to specify which IPsec SA, or pair of IPsec SAs, the expression shall match to. After all you could have several independent VPN tunnels all ending on your machine and thereby a whole bunch of IPsec SAs and SPs. So you need to specify which one you are referring to. Matching those can be done either via the reqid, the spi or the source or destination IP address. You can use the commands ip xfrm state and ip xfrm policy to obtain all of this information. Usually each VPN tunnel has two SAs6), one for each data direction and each SA can be identified by its unique spi number. The reqid is a number which IPsec internally uses to assign SAs to SPs. In contrast to the spi, there is only one unique reqid number which represents both data directions of a VPN tunnel.
The source and destination IP addresses are the ones belonging to the SA. Thus, in case of tunnel-mode those are source and destination IP addresses of the outer IP packet.
But what is spnum? The man-page says… The optional keyword spnum can be used to match a specific state in a chain, it defaults to 0. “State” here means SA. The structure representing an IPsec SA within the Linux kernel is struct xfrm_state, which explains why the man-page calls it “state” and also the command syntax ip xfrm state which lists all SAs. Well, if not explicitly specified, spnum is zero and you can ignore it. However there are cases, where more than one SA is used (on top of each other) to encrypt/decrypt a packet… e.g. one SA to compress the packet and another to encrypt it… again, say yay to the complexity of IPsec.  So,
So, spnum can be used in those cases to specify which of those bundled SAs you are referring to.
But wait a minute. Those IPsec expressions make use of packet meta data as described in the sections above. But, what happens if you place a rule with an IPsec expression in an Nftables chain in a Netfilter hook which is traversed by network packets before the step which actually adds this metadata to the packet? That would e.g. be the case if you would place an ipsec out expression in the Prerouting hook, which is clearly traversed before the mentioned bundle is added to the packet as meta data. The simple answer is, you can't. Nftables only allows you to use these IPsec expressions in Netfilter hooks7) where the mentioned meta data has already been added and will complain if you try to add a rule with an IPsec expression somewhere else. The man-page states this and I show it here in the table in Figure 1.
If you feel uncertain about the exact relation between Nftables tables/chains and Netfilter hooks, then you are welcome to check out my article Nftables - Packet flow and Netfilter hooks in detail, which covers that topic in detail.
| IPsec expression | Allowed in Netfilter hooks |
|---|---|
ipsec in <…> | Prerouting, Input and Forward |
ipsec out <…> | Forward, Output, Postrouting |
To be clear: ipsec out expressions do only match IPsec-related packets which are not encrypted yet. Once those packets are encrypted, the mentioned “bundle” metadata is removed, because the encryption job is done. Thus, those expressions do not match already encrypted packets.
The same applies to ipsec in expressions, just the other way around. They do not match encrypted packets which have not been decrypted yet, due to the sec_path skb extension being added during the decryption step and not before.
However, already/still encrypted packets can easily be matched with common Nftables expressions like meta l4proto esp or udp dport 4500. So this actually isn't a problem, just something you need to be aware of.
Example Site-to-site VPN
Let's reuse the IPsec site-to-site example setup shown in Figure 2, which I already used in my mentioned previous article to explain the flow of IPsec packets in a practical way. It consists of two VPN gateways r1 and r2, which connect their mutual local subnets via IPsec in tunnel-mode, using IKEv2 and ESP.
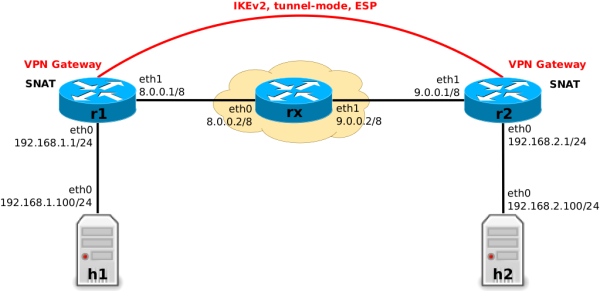
r1 and r2
These two gateways shall do SNAT/masquerade for non-VPN traffic, but not for VPN traffic. This creates a use case which makes it necessary to distinguish between VPN and non-VPN traffic and this time we of course will solve that by means of IPsec expressions. But first, let's ignore the SNAT thing for the moment. I'll get back to that. Let's take a detailed look at packet traversal of VPN traffic on r1 in case of a simple ICMP ping, but this time with focus on where Nftables IPsec expressions could be applied on r1 to successfully match and thereby distinguish between VPN and non-VPN traffic. I merely use an ICMP packet here to stay consistent in my examples. Things wouldn't work any different in case of a UDP or TCP packet.
The VPN tunnel in this example has reqid = 18). The following Figures cover all four possible kinds of IPsec packet flow on r1:
- Figure 3: forwarding and then encrypting+encapsulating a packet
- Figure 4: locally creating a packet and encrypting+encapsulating it before sending
- Figure 5: decrypting+decapsulating a packet and then forwarding it
- Figure 6: decrypting+decapsulating a packet and then locally receiving it
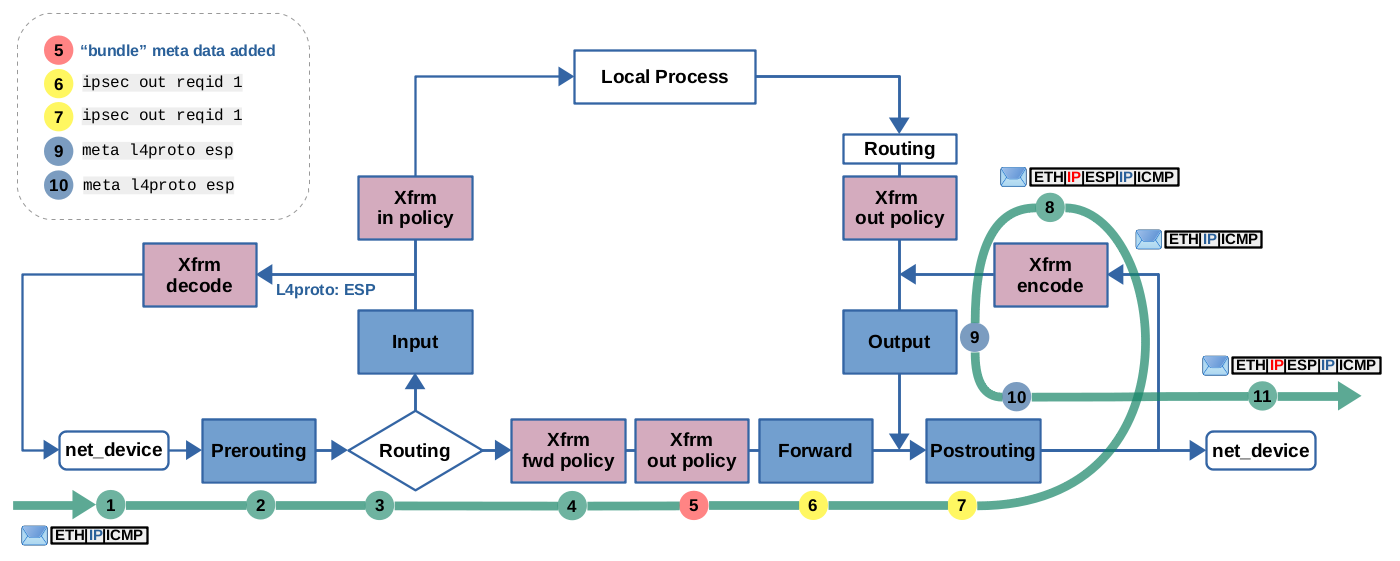
h1 to h2: ICMP echo-request is traversing r1. It is received on eth0, gets
forwarded and then encrypted+encapsulated, before being sent out on eth1. IPsec expressions can be used here in Forward (6) and Postrouting (7) hooks to match the packet, before it gets encrypted+encapsulated (8). After that, the packet can be matched by ESP protocol expression (9, 10). (click to enlarge)

r1 to h2: ICMP echo-request originates on r19). It is encrypted+encapsulated, before being sent out on eth1. IPsec expressions can be used here in Output (4) and Postrouting (5) hooks to match the packet, before it gets encrypted+encapsulated (6). After that, packet can be matched by ESP protocol expression (7, 8). (click to enlarge)
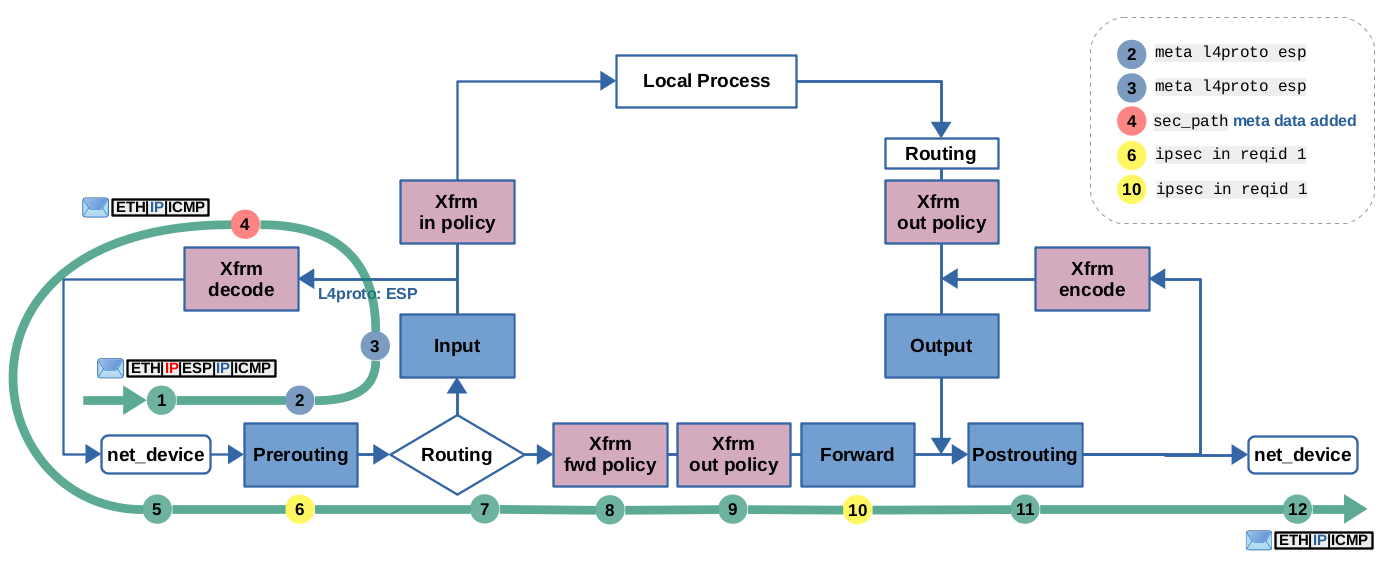
h2 to h1: ICMP echo-request is traversing r1. It is received on eth1, gets
decrypted+decapsulated and then gets forwarded, before being sent out on eth0. The encrypted packet can be matched by ESP protocol expression (2, 3). IPsec expressions can be used here in Prerouting (6) and Forward (10) hooks to match the packet, after it got decrypted+decapsulated (4). (click to enlarge)
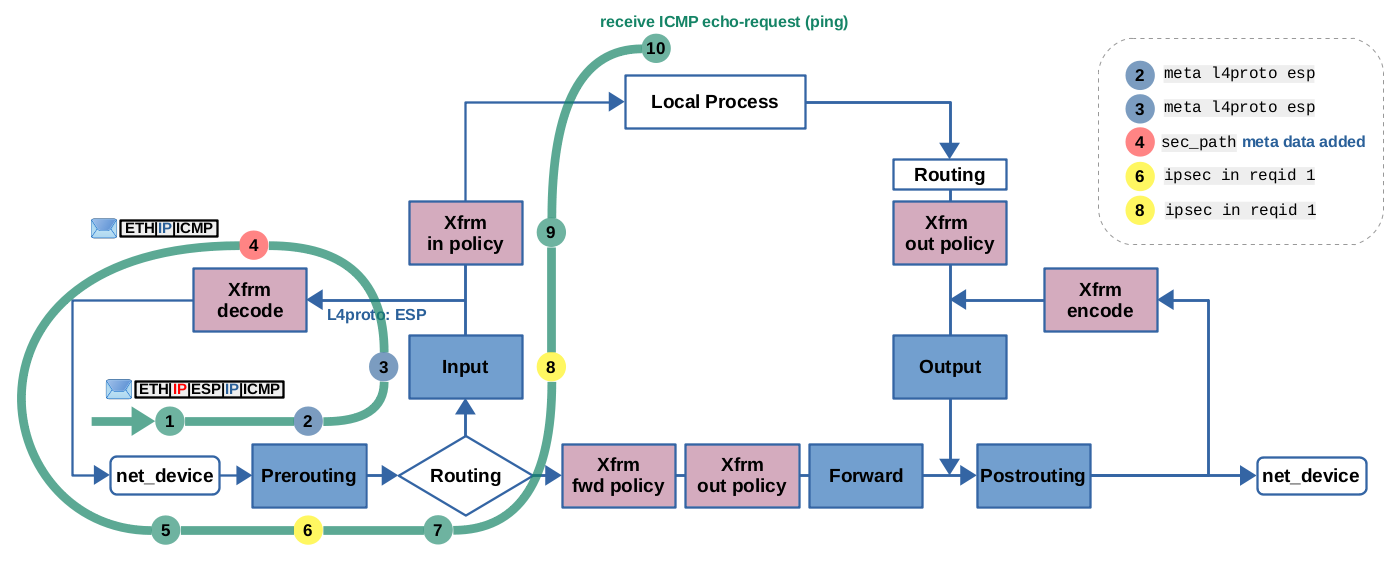
h2 to r110): ICMP echo-request is received by on eth1 of r1, is being decrypted+decapsulated and then locally received on r1. The encrypted packet can be matched by ESP protocol expression (2, 3). IPsec expressions can be used here in Prerouting (6) and Input (8) hooks to match the packet, after it got decrypted+decapsulated (4). (click to enlarge)
Now let's make the example complete by creating the necessary Nftables
rulesets on r1 and r2 to do SNAT for non-VPN traffic and to do normal
forwarding for VPN traffic (this includes allowing new connections both ways
between the peer subnets). In the previous article I intentionally did this in
a crude way by using the peer subnet IP addresses for distinction between VPN
and non VPN-traffic. You can find the resulting rulesets here. These are the very same rulesets, but instead with IPsec expressions:
root@r1:~# nft list ruleset table ip nat { chain postrouting { type nat hook postrouting priority srcnat; policy accept; oif eth1 ipsec out reqid 1 accept oif eth1 masquerade } } table ip filter { chain forward { type filter hook forward priority filter; policy drop; iif eth0 oif eth1 accept iif eth1 oif eth0 ct state established,related accept iif eth1 oif eth0 ipsec in reqid 1 ct state new accept } }
root@r2:~# nft list ruleset table ip nat { chain postrouting { type nat hook postrouting priority srcnat; policy accept; oif eth1 ipsec out reqid 1 accept oif eth1 masquerade } } table ip filter { chain forward { type filter hook forward priority filter; policy drop; iif eth0 oif r2 accept iif eth1 oif r2 ct state established,related accept iif eth1 oif r2 ipsec in reqid 1 ct state new accept } }
In a real world setup you should make use of the strongSwan _updown script, which has access to the reqid value, to dynamically add and remove Nftables rules containing IPsec expressions on VPN tunnel build-up and teardown. Adding the reqid value statically as I did here, after obtaining it from the output of the ip xfrm state command, is not a wise idea, because the value could change on every successive IKE handshake. I'll try to cover that in a possible future article.
Iptables expressions
Iptables provides equivalent IPsec expressions among its extensions. Those are documented in man iptables-extensions(8). Please search for the heading policy within the man-page. My focus in this article is on Nftables, so I did not
experiment with Iptables in that regard. However, I took a look at the source code, which is net/netfilter/xt_policy.c, and I can confirm that those expressions are very similar to their Nftables equivalent. The semantics are more or less the same, meaning they make use of the very same packet meta data and can be used in the same hooks as the Nftables ones. Here a syntax example which should be equivalent to what I used above for Nftables:
-m policy --pol ipsec --proto esp --reqid 1 --dir in -m policy --pol ipsec --proto esp --reqid 1 --dir out
Context
The described behavior and implementation has been observed on a Debian 10 (buster) system with using Debian backports on amd64 architecture.
- kernel:
5.10.46-4~bpo10+1 - nftables:
0.9.6-1~bpo10+1 - strongswan:
5.7.2-1+deb10u1
Feedback
Feedback to this article is very welcome! Please be aware that I did not develop or contribute to any of the software components described here. I'm merely some developer who took a look at the source code and did some practical experimenting. If you find something which I might have misunderstood or described incorrectly here, then I would be very grateful, if you bring this to my attention and of course I'll then fix my content asap accordingly.
References
published 2022-01-30, last modified 2022-08-07
/usr/lib/ipsec/_updown, already places Iptables rules with IPsec expressions like the ones I am explaining here. However, an Nftables solution there is still missing and even if it wouldn't… who can assure that those rules fit perfectly in the concept of your potentially already existing Iptables/Nftables ruleset? Usually they do not, so in reality you might nearly always need to create your own version of that script… but that's a topic for another article… if I find time to write it.ip xfrm state in the previous article.192.168.1.1 of eth0 interface of r1 is used if destination IP address belongs to peer subnet. This way the traffic selectors of the IPsec dir out policy work as intended, also in this case.192.168.1.1, which is assigned to eth0 and belongs to the local subnet behind r1.